
Bruce Desmarais will teach Machine Learning on June 11-14, 2024. This seminar provides a comprehensive introduction to machine learning. You will walk away an understanding of the core concepts, practical applications, and the ability to leverage machine learning techniques to enhance your own research endeavors.
In my previous blog post, I shared my early journey into the world of machine learning (ML), introducing its fundamental concepts and how they intertwined with my early experiences as a researcher. This semester, while teaching a graduate-level ML course at Penn State, I realized that there was a pressing need to connect core machine learning principles to state-of-the-art artificial intelligence (AI) technology. Students in this class are far more interested in understanding and applying tools associated with AI than they were when I taught the same course two years ago.
In this post, I delve into the exciting and rapidly evolving nexus between ML and AI–a topic not only of academic interest but one that resonates with the astonishing advancements making headlines today. I see four properties that lie at the heart of ML that are unique relative to most other advanced statistical methods, and which are amplified in the current capabilities of AI technologies.
LEARN MORE IN A SEMINAR WITH BRUCE DESMARAIS
The Primacy of Prediction
Optimizing the predictive performance of a model is a goal in nearly every ML project. This laser focus on prediction has evolved into the “generative” capabilities of modern AI technology. Goodfellow et al. (2014) introduced Generative Adversarial Networks (GANs), a groundbreaking concept where two neural networks compete with each other to generate new, synthetic instances of data that can pass for real data. This leap from predictive to generative models is transformative, enabling applications where AI doesn’t just anticipate outcomes but actively creates text, art, music, and code.
The Generalizability of Models
We are always concerned to some degree with the external validity of inferences drawn from statistical analysis. In ML, there is even greater emphasis on the accuracy of models in the context of new data. An extension of this property in contemporary ML is the development of models that transcend domain-specific boundaries. The ability to train and estimate models using massive corpora of text and large collections of images in ways that adapt seamlessly across various fields is paramount to the functioning of AI tools. A study by Yosinski et al. (2014) demonstrated the ability of deep neural networks to transfer knowledge learned in one domain to another, a concept known as transfer learning. This versatility not only demonstrates the robustness of ML models but also their interdisciplinary and inter-industry potential.
Data Volume, Scope, and Complexity
One of the features that distinguishes many ML methods is that they continue to improve significantly in performance when the volume of data is far beyond the sample size of hundreds (or low thousands) where most conventional statistical methods tend to plateau. With conventional methods, the structure of the model is fixed and does not adapt to the size and complexity of the data. A signature attribute of ML methods (e.g., random forests, neural networks), on the other hand, is that they can grow in complexity as the size and scope of the data can support the expanded parameter space. Halevy, Norvig, and Pereira (2009) highlight the importance of volume and diversity of data in improving machine learning algorithms. This expansion challenges us to develop algorithms capable of deriving insights from massive, complex, high-dimensional data, a key to advancements in areas like natural language processing and image recognition.
Pushing the Computational Boundaries
Although many advanced statistical methods can be computationally burdensome, the intricate relationship between the performance of the methodology and the extent of the computational resources available is a foundational characteristic of ML. The use of graphics processing units (GPU), which enable parallel computing on an unprecedented scale, has helped to advance the development of AI technology. More generally, the development of scalable computational resources is revolutionizing ML. Dean et al. (2012) discuss the implementation of large-scale distributed neural network systems, showing how computational power can redefine the boundaries of AI. This surge in computational capacity allows for training larger models and reducing computation time, driving AI’s rapid progression.
A Representative Experience
In a recently published paper (Kim et al. 2022), my research group made its first foray into the use of large language models (LLMs) for an ML task. LLMs lie at the foundation of text-related AI technologies such as ChatGPT. In this project, we studied when and how U.S. state legislators tweeted about the COVID-19 pandemic. After collecting a large corpus of state lawmakers’ tweets, our first task was to identify which tweets were about the pandemic. We fit several widely-used ML algorithms (including different specifications of Random Forests and XGBoost) to word/hashtag counts. That’s the standard approach to predictive model development with text data.
However, my collaborator on this project, Taegyoon Kim, suggested that we try a new framework using deep neural networks that had been pre-trained on massive text corpora. The specific model that we used was BERT (Bidirectional Encoder Representations from Transformers). It has over one hundred million parameters and was trained on a massive corpus of digitized books, as well as English Wikipedia pages (Delvin et al. 2018).
Instead of starting from scratch in estimating a model, the approach used with LLMs is to fine-tune the existing model to fit your specific data and task. Using the tweet text data, we fine-tuned BERT for the task of predicting a sample of 2,000 tweets that we had already hand-coded for relevance to the COVID-19 pandemic. We found that the fine-tuned BERT model out-performed the conventional ML approaches, achieving predictive scores that were at least 10% better.
In this project, we observed first-hand the seamless relationship between foundational ML methods and the cutting-edge technology that has facilitated the development of modern AI. As an illustration of our results from the BERT classifier, the figure below is a visualization of the terms that separated tweets that were and were not pandemic related.
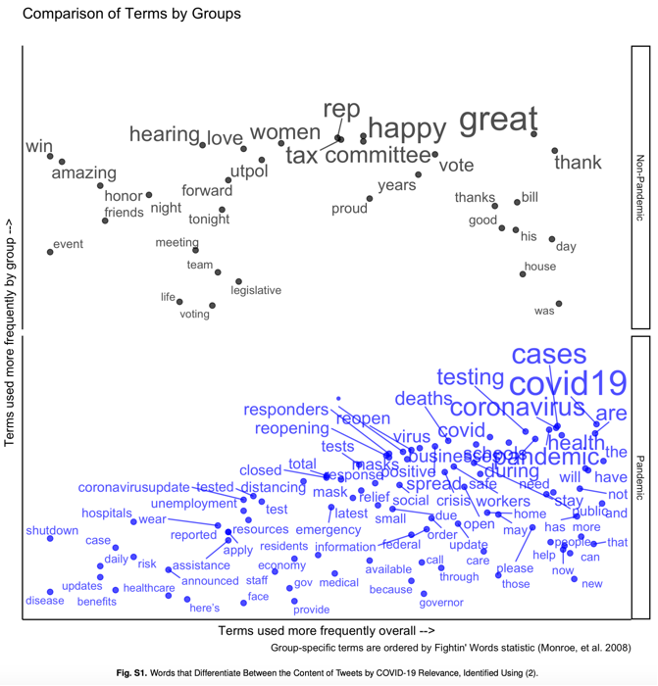
Conclusion
The intersection of ML and AI is more than a mere academic topic; it’s a vibrant, evolving landscape shaping our future. By understanding and embracing these four foundational pillars through core training in ML, we can position ourselves to be expert users, and perhaps even contribute to the latest AI technology going forward.
References
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
Yosinski, J., Clune, J., Bengio, Y., & Lipson, H. (2014). How transferable are features in deep neural networks? In Advances in neural information processing systems (pp. 3320-3328).
Halevy, A., Norvig, P., & Pereira, F. (2009). The unreasonable effectiveness of data. IEEE Intelligent Systems, 24(2), 8-12.
Dean, J., Corrado, G., Monga, R., Chen, K., Devin, M., Le, Q. V., … & Ng, A. Y. (2012). Large scale distributed deep networks. In Advances in neural information processing systems (pp. 1223-1231).
Kim, T., Nakka, N., Gopal, I., Desmarais, B.A., Mancinelli, A., Harden, J.J., Ko, H. and Boehmke, F.J., 2022. Attention to the COVID‐19 pandemic on Twitter: Partisan differences among US state legislators. Legislative studies quarterly, 47(4), pp.1023-1041.
Devlin, J., Chang, M.W., Lee, K. and Toutanova, K., 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.