
In my courses and books on longitudinal data analysis, I spend a lot of time talking about the between-within model for fixed effects. I used to call it the hybrid model, but others have convinced me that “between-within” provides a more meaningful description.
Last week my long-time collaborator, Paula England, asked me a question about the between-within model that stumped me at first. When I finally figured out the answer, I realized that it could potentially be important to anyone who uses the between-within method. Hence, this post.
LEARN MORE IN A SEMINAR WITH PAUL ALLISON
Here is Paula’s project, co-authored with Eman Abdelhadi. They have a large, cross-sectional sample of adult women from approximately 50 countries. They are estimating a logistic regression model for a dichotomous dependent variable: whether or not a woman is employed. One of the independent variables is also dichotomous: whether or not a woman is a Muslim (coded 1 or 0). In order to control for all between-country differences, they estimate a between-within model with the following characteristics:
- a random-intercepts model with countries as clusters.
- a “within” predictor that is the Muslim indicator (dummy variable) minus the country mean of that variable.
- a “between” predictor that is the country mean, i.e., the proportion Muslim.
- other control variables at both the person level and the country level.
The coefficient for the within predictor is very close to what you would get from a classic fixed effects estimator, as estimated by conditional logistic regression. (My 2014 post discusses why they are not identical). So it represents the effect of being Muslim on employment, controlling for all country-level variables, both observed and unobserved.
Here is the question. Can you interpret the coefficient for the between predictor (proportion Muslim) as the effect of living in a country that is more or less Muslim, regardless of whether a person is personally a Muslim? In other words, can you interpret the between coefficient as a contextual effect?
Surprisingly, the answer is no. By construction, the within variable is uncorrelated with the between variable. For that reason, the coefficient for proportion Muslim does not actually control for the person-level effect of being Muslim.
The reason I never thought about this question before is that I primarily use the between-within model for longitudinal data, with repeated measurements clustered within persons. In that setting, the coefficients for the between variables are usually uninteresting or misleading. But when applied to other kinds of clustering, the estimation and interpretation of “between” effects can be quite important.
Fortunately, there’s a simple solution to the problem: Estimate the model using the original Muslim indicator rather than the deviation from its country-level mean. This model is mathematically equivalent to the original between-within model—the coefficients for the Muslim indicator and for all the control variables will be exactly the same. But the coefficient for the proportion Muslim will change, and in a predictable way. Here is the algebra:
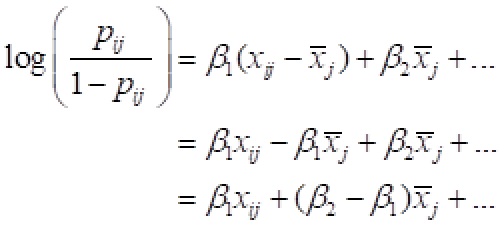
In these equations pij is the probability of employment for person i in country j, xij is the Muslim indicator for person i in country j, and x-bar-j is the mean of the Muslim indicator in country j.
The first equation is the usual formulation of the between-within model. The second equation is the algebra that gets us to the third equation. That equation is the new formulation of the model with xij and x-bar-j as predictors. Notice that the coefficient of x-bar-j in the third equation can be found by subtracting the coefficient for the within effect from the coefficient for the between effect in the first equation.
So you don’t actually have to re-estimate the model to get the contextual effect. You can just take the difference in the coefficients in the standard between-within model. Furthermore, testing whether those coefficients are the same or different (which is usually done to test fixed vs. random effects) is equivalent to testing for the existence of a contextual effect.
Keep in mind that although the coefficient for x-bar-j in the third equation can be interpreted as a contextual effect, it does not control for any unobservables. So it could be biased by the omission of country-level variables or person-level variables that affect employment and are correlated with proportion Muslim. Note, also, that the fact that the person-level variable is dichotomous in this example is completely incidental. The same logic would apply if xij were continuous.
Comments
Hi Professor,
My study looks at creating an index describing the long-term land use plans of cities that cover a period 15 years or so. I want to relate it to actual expenditures of cities. Thus my variable of interest is time invariant (a land use plan will only have one score over 15 years) and my dependent variable (expenditures) are rime varying. Covariates are both time invariant (geographic) and time varying (election results etc). Due to this, I am considering applying the between-within effects model. The clustering will be at the city level. You mention in this article that “In that setting, the coefficients for the between variables are usually uninteresting or misleading. But when applied to other kinds of clustering, the estimation and interpretation of “between” effects can be quite important.” Why is clustering at the city (person) level misleading and how can I improve the analysis since my variable of interest is the index which is time invariant? Thank you so much!
If land use plans are your key variable of interest, it doesn’t matter how you code the time-dependent variables. Either method described in my blog post will produce the same coefficient for land use. When I said “the coefficients for the between variables are usually uninteresting”, I was referring to the means of the time-dependent variables, not the truly time-invariant variables.
On the other hand, in order to get the standard errors and p-values for land use right, you have to adjust for clustering, either by including a city random effect or by using cluster-robust standard errors (or both). Also, you need to keep in mind that some of your time-varying covariates may be mediating the effect of land-use. So you may want to estimate models both with and without those variables in order to estimate the total effect and direct effect of land use. And you may even want to estimate structural equation models that explicitly build in those variables as mediators.
Dear Professor. Thank you for this helpfull text. I am struggling with the appropriate modeling for my data. I have event history data in person-month format. Individuals are also grouped into clusters (villages, neighborhoods). I want to test the effect of a time-varying explanatory variable (conflict exposure, dichotomous or quantitative) measured at the village or neighborhood level on the probability of experiencing first pregnancy during adolescencce(dichotomous dependent variable). The Hausman test had indicated that the fixed effects model was appropriate, but I don’t want to use a fixed effects model because I am also interested in the effect of a time-invariant variable (place of residence, urban or rural) and its interaction with the explanatory variable (conflict exposure). I would like to use the within-between model. Two questions. Does it make sens to estimate the between effect (mean of war exposure) and the within effect (war exposure minus the mean for each cluster) for the conflict exposure variable? Is it relevant to add a random effect at both the individual level(women level) and the cluster level (villages, neighborhoods)? Do you have an alternative model to propose?
Yes, I think the between-within approach could work for your research question. However, if you want to interpret the between effect as a true contextual effect, you should follow the advice in my blog post and not express the “within” effect as a deviation from the mean. I do think it’s worth having a random effect at the cluster level in order to get the standard errors right. Alternatively, you could just do cluster-robust standard errors. But I don’t recommend including a random effect at the person level. Because your event is not repeated, the individual random effect would only be weakly identified.
Dear Professor, I’m following up on the previous question. My explanatory variable (exposure to conflict) is measured at the village (cluster) level, but these villages are part of regions. I have no other variable that is measured at the level of regions. Which of the three approaches is better: 1) add a fixed effect at the region level (when I do this, my explanatory variable loses statistical significance); 2) add a clustered standard error at the region level; 3) ignore the region variable.
Well, ordinarily I would recommend adding a fixed effect at the region level. That would control for all characteristics of the regions. However, that would include the degree of conflict at the regional level. And if villages within regions have similar levels of conflict, that might “control away” what’s of greatest interest to you. If you have no variables of interest at the regional level, I don’t think there’s much need for standard errors clustered by region, especiall if the number of regions is on the small size (e.g., <15). So, a case could be made for just ignoring region.
Thank you for this clarification. In the example above, the nesting includes individuals within counties. I was wondering if the same strategy should be employed if you want to properly interpret the between-individual coefficient when using longitudinal data (i.e., repeated measurements clustered in persons)?
The answer is yes, however, in the longitudinal setting, contextual effects are generally less meaningful. To use the example in the post, if a person is living in a country with a high proportion of Muslims, he or she is potentially affected by all the individuals in that country and the general culture that those individuals produce and enact. For longitudinal data, on the other hand, it is less sensible to think that the person at time t is affected by the average of all the values of the predictors at all points in time.