
Gain hands-on experience with machine learning tools and methodologies in Machine Learning, taught by Professor Desmarais. You’ll deepen your understanding of how machine learning can be applied to advance your own research projects.
When researchers use machine learning (ML) methods, they often want to use those methods for intermediate steps in the analysis rather than as the final analytical step. In other words, they want to use ML tools to build ML pipelines. What is an ML pipeline? It is a structured workflow that automates the process of preparing data, training models, and deploying them for predictions or analysis.
LEARN MORE IN A SEMINAR WITH BRUCE DESMARAIS
Here’s an example from one of my recent projects. Since the start of the Covid pandemic in the spring of 2020, my team has been collecting social media posts made by state legislators in the U.S. In our first study, we analyzed patterns of who, when, and with what frequency lawmakers posted on Twitter about the pandemic. Of course, the first step was to identify whether or not a tweet was “about the pandemic.”
To accomplish this, we developed a machine learning measurement pipeline, a typical application in the social sciences. The pipeline consisted of iteratively hand-labeling a small sample of tweets for pandemic relevance, training several machine learning models to predict the hand labels, and then labeling more tweets in order to assess and improve the performance of the models.
This iterative training and labeling approach is called active learning. The best-performing ML model we developed was then used to identify all of the pandemic-relevant tweets in our data set. From there we developed conventional regression models in order to study which legislators discussed the pandemic on Twitter and at what time it was discussed.
To implement an iterative pipeline like this, there’s one question that must be answered: “How do I know when my model is good enough to stop?” This question is fundamental and often more complex than it appears. The answer depends on the specific goals of the project, the context in which the model will be used, and the trade-offs that stakeholders are willing to accept. There are two general approaches that we commonly find in the literature. The first is to compare the model to common benchmarks for similar tasks. The second, in the absence of clear benchmarks, is to attempt a fairly exhaustive set of approaches.
Benchmarking
One way to determine if your model is “good enough” is to measure its performance against established benchmarks from similar applications on comparable datasets. Benchmarks provide a reliable reference point, whether drawn from peer-reviewed literature, industry standards, or public challenges. If your model outperforms the accuracy, precision, recall, or other relevant metrics of previously published models on a similar task, it is a strong indication that it meets or exceeds expectations.
For our study on legislators’ tweets, we were able reference an extensive literature on binary relevance classifiers of tweets, and we found that precision and recall values were typically between 0.75 and 0.95 (see, e.g., models for disaster-relevance, social unrest, and vaccination relevance). We compared random forests and XGBoost models, both with different featurizations of the text, along with a model that was quite new at the time–the BERT language model.
As shown in Table 1, the BERT model performed the best, and was well within common benchmarks reached in the literature. So, we decided to stop iterating on the active learning and proceed with analysis of the classified tweets.
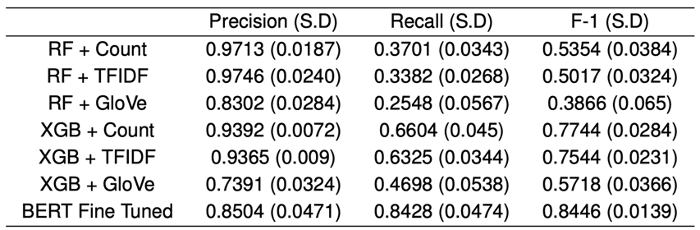
Table 1: Classifier performance in predicting COVID-19 relevance of lawmakers’ tweets.
Exhaustive Search
In the absence of established benchmarks, determining if a model is good enough becomes more subjective and iterative. The key is to ensure that you have exhausted all reasonably feasible methods to improve it. This includes testing a variety of algorithms, tuning hyperparameters, and experimenting with data preprocessing techniques.
You should always try to anticipate potential critiques and suggestions from peer reviewers and ensure that these avenues have been explored. Beyond the technical improvements, reflect on whether the model aligns with the practical needs of the stakeholders. If additional gains in performance are only achievable through impractical or prohibitively expensive approaches, it may be time to conclude the development phase.
This approach requires balancing technical rigor with pragmatic decision-making to ensure the model is not only “good enough” but also ready for real-world application. As an example, see this study in which Kumar et al. develop a pipeline to identify social media images of disaster-affected cultural heritage sites.
Pre-Trained Methods
A relatively recent development is the availability of pre-trained deep learning (e.g. large language) models that can be used to classify items for relevant attributes. For example, there are multiple models available that can be used to identify “toxic” language from text. Two well-known examples are the Perspective and Detoxify models. By integrating one of these models into your pipeline, you are naturally adhering to widely accepted standards.
Unlike traditional benchmarking, where you compare your model’s performance with others in the literature or with public datasets, leveraging a pre-trained model means you are re-using the exact same model that others rely on. This not only ensures consistency in how tasks are operationalized but also aligns your work with a de facto standard in the field.
My group recently used the Detoxify model in a study of incivility in state lawmakers’ tweets and Facebook posts. The Detoxify model takes text as an input and outputs a probability that the text contains toxic language. We used human labeling of a sample of social media posts to determine that the best-performing threshold at which to define a post as toxic was a Detoxify probability of 0.82. In short, we used a standard model but adapted its application to the unique characteristics of our data. The results of our civility classification (as well as related results from identifying low-credibility content), are presented in Figure 1.
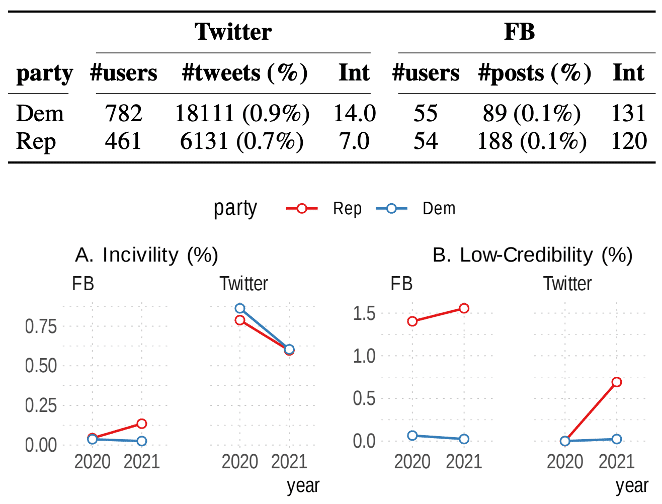
Figure 1: Rates of incivility and low-credibility in lawmakers’ tweets and Facebook posts.
Final Thoughts
Determining when an ML pipeline is good enough is both a technical and practical decision. It involves balancing the goals of the project with the constraints of time, resources, and stakeholder needs. In my workshops, I emphasize the importance of defining clear objectives, selecting appropriate evaluation metrics, and considering both robustness and interpretability. By following these principles, researchers and practitioners can build models that are not only methodologically sound but also actionable and reliable.