
To learn more about machine learning methodologies, core concepts, practical applications, and how to leverage these techniques in your own research, join Professor Bruce Desmarais for Machine Learning.
When I teach machine learning (ML), I find that many people think there is an inherent tension between models that provide accurate predictions and those that are easily interpretable. However, this dichotomy can be misleading. The pursuit of accurate predictions need not come at the expense of interpretability. In fact, these goals can be aligned to enhance both what can be predicted from an ML model and the degree to which the model can yield interpretable patterns in the underlying data. In this post, I will explain how that can be accomplished.
LEARN MORE IN A SEMINAR WITH BRUCE DESMARAIS
Prediction bolsters interpretation
Researchers commonly model their data with the objective of understanding the process that generated the data by interpreting patterns in the model’s estimates. However, for the model to be reliably interpretable, it must also predict reasonably well. The rationale is straightforward: predictions that closely mirror the data well are inherently more reflective of the process that generated the data.
The first step in understanding the interpretability of ML methods is to recognize that a model needn’t distill the data down to simple linear relationships to provide clear substantive insights regarding the underlying process. On the contrary, while simple models may be easily interpretable, those interpretations can easily be wrong or misleading. Thus, by enhancing predictive performance, we not only get more reliable forecasts but also more confidence in the insights derived from those predictions.
Here’s an example from my own research, showing how interpretation and prediction can work hand-in-hand in ML. In a publication co-authored with Skyler Cranmer that appeared in Political Analysis, we used a variety of machine learning methods to develop models that perform as well as possible at forecasting the onset of international militarized disputes. One question we asked in this study is whether conflict onset is driven by very recent developments in the world, both within and across countries, or if it is a slower or longer-memory process.
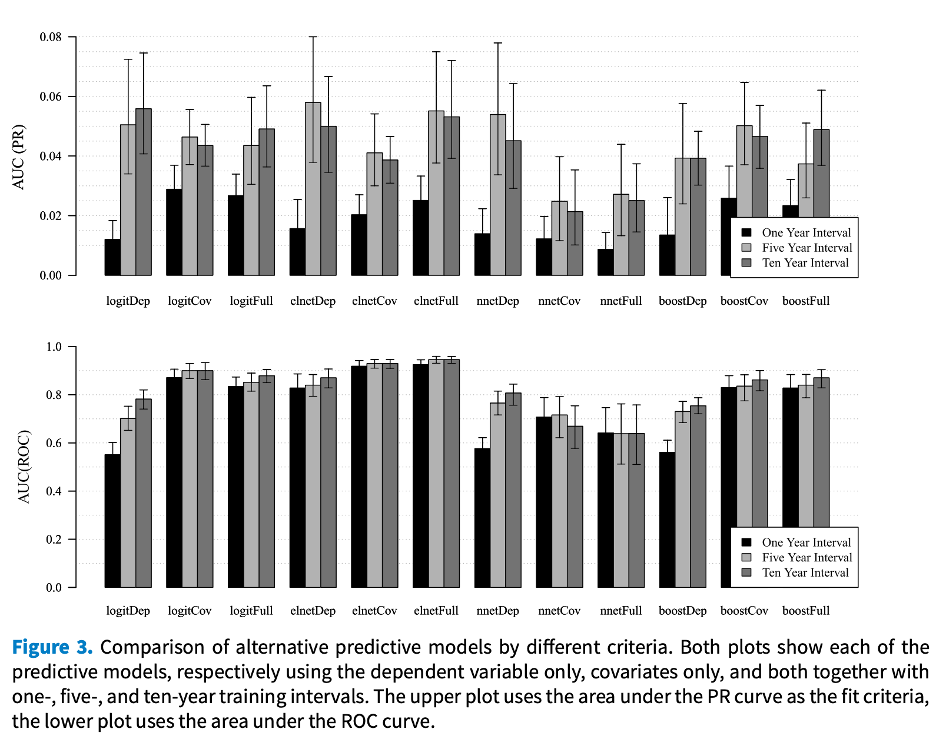
To explore this question, we fit a total of twelve different ML models, each optimized for prediction, in which the predictive features (i.e., covariates) were based on three different time intervals—one for the previous year, one that aggregates over the previous five years and one that aggregates over the previous ten years. Below is a figure that summarizes our results.
The two bar charts in the figure give two alternative measures of out-of-sample predictive performance on the y-axis. The bars along the x-axis are based on the specific method we used. The results are pretty clearcut. The five and ten-year intervals did about equally well, with some variability across the different methods. However, both the five and ten-year intervals performed significantly better than the one-year interval.
We concluded that the onset of international conflict cannot be predicted based on the recent past alone—a result that challenges the common practice of modeling conflict based on data with a one-year lag. We are confident in this finding since we used methods that are designed to provide the best predictive performance possible given the data.
Learning about model biases from predictive variability
Interpretation of the relationships in our models is indispensable. However, substantive interpretation of a model can also be informed by the model’s shortcomings. Argyle and Barber (2022) presented a compelling illustration of how this works. Using a popular method known as Bayesian Improved Surname Geocoding (BISG), they investigated the biases in predicting individuals’ race from administrative records. They found that the performance of the predictions varied significantly with the demographic and economic attributes of the individuals, indicating underlying biases. However, by integrating BISG estimates into more sophisticated ML methods, they were able to correct these biases, showcasing how variations in predictive performance itself can serve as a key point of interpretation when learning from a model.
This study also illustrates the practice of “boosting,” a pervasive feature of contemporary machine learning. With boosting, a predictive model is constructed by aggregating predictions over multiple simpler models. The models are built iteratively, with each new model focusing on improving predictions of observations that are predicted poorly by the models that preceded them (Dietterich 2000). What Argyle and Barber discovered was that the predictive shortcomings in state-of-the-art methods correlated with important demographic attributes of individuals. To address this bias, the existing methodology needed to be boosted.
Concluding thoughts
When I teach ML, I cover method-specific approaches to interpreting the complex relationships that ML models represent. Each ML method, e.g., support vector machines, generalized additive models, and random forests, has a unique corresponding toolkit for interpretation. By understanding these tools, we can unpack the relationships represented in our models, thereby leveraging the added confidence we gain through focusing on models that predict well.
If you’re interested in learning more, I highly recommend Schmueli (2010) on the topic of how predictive modeling relates to explanation. Predictive models can and should be interpreted. However, if your ultimate goal is explanatory, you should think carefully about whether and how predictive model building fits your overall objectives.
References
Argyle, Lisa P., and Michael Barber. “Misclassification and bias in predictions of individual ethnicity from administrative records.” American Political Science Review (2022): 1-9.
Cranmer, Skyler J., and Bruce A. Desmarais. “What can we learn from predictive modeling?.” Political Analysis 25, no. 2 (2017): 145-166.
Dietterich, Thomas G. “An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization.” Machine learning 40 (2000): 139-157.
Shmueli, Galit. “To Explain or to Predict?.” Statistical Science 25, no. 3 (2010): 289-310.